
데이터 세트 구축 (Splitting Data)
Training and Test Sets
데이터 세트를 두 부분집합으로 나눌 수 있다.
- training set : 모델 학습을 위한 부분집합
- test set : 학습한 모델을 테스트 하기 위한 부분집합

좋은 성능을 가진 모델을 만들기 위해 테스트 세트에 충족시켜야 할 조건이 있다.
- 의미 있는 결과를 얻을 수 있을 만큼 충분한 수를 가져야 한다.
- 테스트 세트에도 전체 데이터 세트의 특성이 고르게 반영되어야 한다. 즉, training set과 test set의 특성이 같아야 한다.
테스트 세트가 위의 두 조건을 충족할 때, 새로운 데이터에도 일반화가 잘 되는 모델을 만들 수 있다. 테스트 데이터는 새로운 데이터의 대리로서 작용하는 것이다. 예를 들어, 다음 그림을 보자. 이 모델은 training set에 대해서 매우 간단한 모델로 학습을 하였다. 두 특성을 완벽하게 분류해내지 못하고 몇 개의 오분류된 결과를 내는 것을 확인할 수 있다. 그러나, 이 모델을 test set으로 테스트 했을 때도 거의 동일한 수준으로 예측을 하는 것을 확인할 수 있다. 즉, 이 단순한 모델은 training set에 대해 과적합되지 않았다는 것을 알 수 있다.
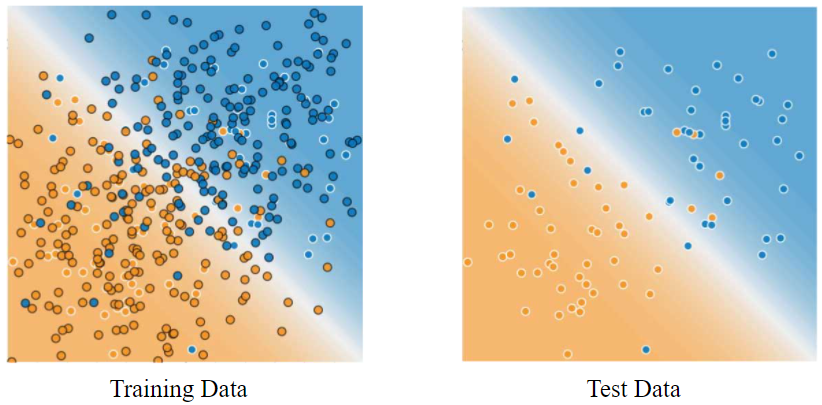
절대로 test set을 학습에 활용해서는 안된다. 꼭 명심하길 바란다. 만약 학습이 끝난 후 결과를 확인하는 평가 지표에서 놀라울 정도로 좋은 정확도가 나왔다면, 실수로 테스트 세트가 학습에 섞여 들어갔을 수도 있다. 다시 한 번 확인해보는 과정이 필요하다.
예를 들어, 스팸 메일을 구분하는 모델을 만들기 위해 제목, 본문, 보낸 사람의 이메일 주소를 특성으로 사용한다고 가정하자. 데이터를 training set : test set = 80% : 20% 비율로 나누어 학습을 했고, 학습 후 모델은 training set, test set 모두에서 99%의 정확도를 보였다. 이 때, training set보다 test set의 정확도가 낮을 것을 예상하고 다시 한 번 확인 하여 training set과 test set의 많은 부분이 중복되었다는 것을 발견할 수 있었다. 중복되는 메일들을 제거하는 것을 잊은 것이다. 이렇게 되면, 모델을 실제로 사용하기 위해 새로운 데이터에 적용할 때, 일반화가 얼마나 잘 될 것인지 측정할 수 없다.
Validation set
위에서 Data set를 모델이 학습하는데에 사용하는 training set과 모델을 테스트하는데에 사용하는 test set으로 분할하는 방법을 알아보았다. 이렇게 두 개로 분할했을 때의 workflow를 보면 다음과 같다.
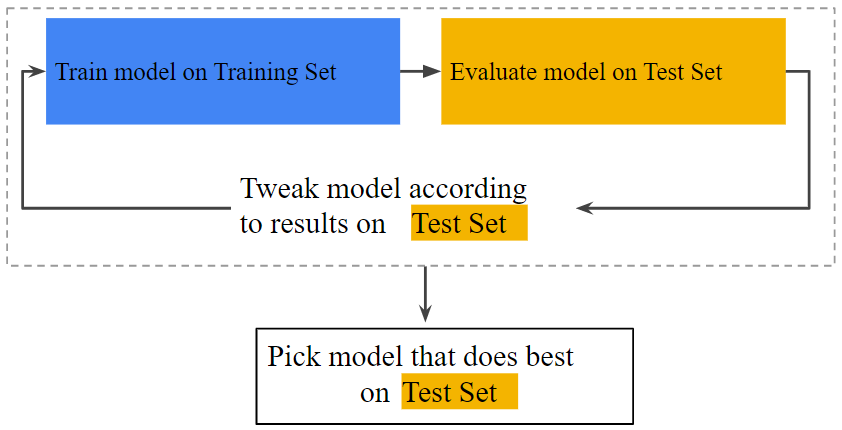
위의 그림에서 “Tweak Model”은 learning rate 수정, 특성 추가 또는 제거, 아니면 처음부터 완전히 세로운 모델 설계와 같은 모델에 대한 모든 것을 수정하는 것을 의미한다. 이 workflow가 끝나면 test set에 대해 가장 성능이 좋은 모델을 선택한다.
data set을 두 개의 set로 나누는 것은 좋은 아이디어이지만, 만능은 아니다. 다음과 같이 세 개의 set으로 나누는 것에 의해 모델이 과대적합 되는 것을 크게 줄일 수 있다.

validation set을 사용하여 training set에 대한 학습 결과를 평가하고, validation set을 통과 한 뒤에 test set을 사용하여 평가를 다시 확인하는 것이다. validation set을 사용하여 개선된 workflow를 보면 다음과 같다.
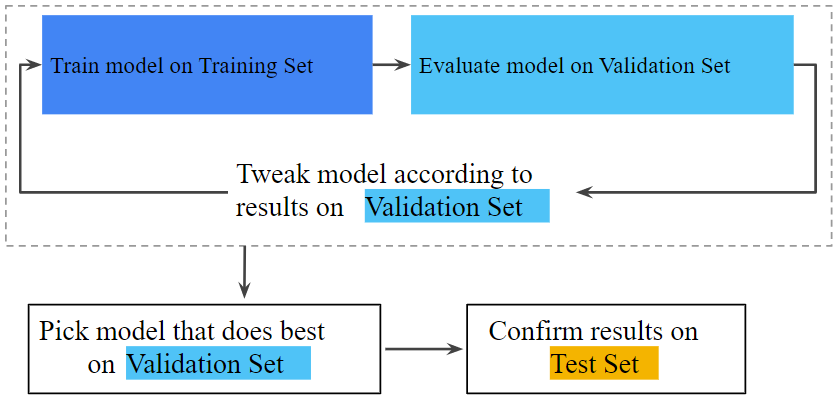
이 개선된 workflow는 :
- validation set에 대해 성능이 가장 좋은 모델을 선택한다.
- test set로 모델을 한번 더 평가 한다.
이는 test set가 모델의 학습에 섞여 들어가는 문제를 줄일 수 있기 때문에 더 좋은 workflow이다.
※ 참고
Google Developer - Splitting Data
Google Developer - Another Partition