
추천 시스템: 조회, 채점, 순위 재지정 (Retrieval, Scoring, Re-ranking)
조회 (Retrieval)
임베딩 모델을 가지고 있다고 가정하자. 사용자가 주어진다면 어떤 items를 추천할 것인지 어떻게 결정할 것인가?
서비스 시간에 query가 주어지면 다음 중 하나를 수행하여 시작한다.
- 행렬 분해 모델의 경우,
query또는 사용자 임베딩은 정적으로 알려져 있으며, 시스템은 사용자 임베딩 행렬에서 간단히 조회할 수 있다. - DNN 모델의 경우, 시스템은 특성 벡터 x에서 네트워크를 실행하여, 서비스 시간에
query임베딩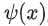 을 계산한다.
을 계산한다.
query 임베딩 q가 있으면 임베딩 공간에서 q에 가까운 item 임베딩 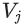 을 검색한다. 이것은 최근접 이웃(nearest neighbor) 문제이다. 예를 들어, 유사도 점수
을 검색한다. 이것은 최근접 이웃(nearest neighbor) 문제이다. 예를 들어, 유사도 점수 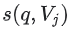 에 따라 상위 k개의
에 따라 상위 k개의 items를 반환할 수 있다.
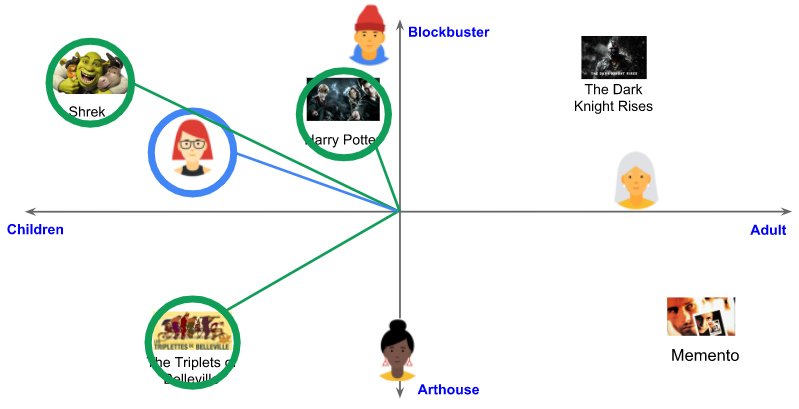
연관 항목 추천에서도 유사한 접근 방식을 이용할 수 있다. 예를 들어, 사용자가 YouTube 영상을 보고 있을 때, 시스템은 먼저 해당 item의 임베딩을 조회한 다음, 임베딩 공간에서 가까운 다른 items의 임베딩 을 찾을 수 있다.
대규모 조회 (Large-Scale Retrieval)
임베딩 공간에서 최근접 이웃을 계산하기 위해, 시스템은 모든 잠재적 후보에 대해 남김없이 점수를 매길 수 있다. 매우 큰 코퍼스에 대해 완전 채점은 비용이 많이 들 수 있지만, 다음 전략 중 하나를 사용하여 더 효율적으로 만들 수 있다.
query임베딩이 정적으로 알려진 경우, 시스템은 오프라인에서 완전 채점을 수행하고 각query의 상위 후보 목록을 미리 계산하고 저장할 수 있다. 이것은 연관 항목 추천에 대한 일반적인 관행이다.- 대략적인 최근접 이웃을 사용한다.
채점 (Scoring)
후보 생성 후, 다른 모델은 생성된 후보에 점수를 매기고 순위를 지정하여 표시할 items 집합을 선택한다. 추천 시스템에는 다음과 같이 서로 다른 소스를 사용하는 여러 후보 생성기가 있을 수 있다.
후보 생성기 소스의 예
- 행렬 분해 모델의 연관 항목
- 개인화를 설명하는 사용자 특성
- ‘현지’ vs ‘원거리’
items. 즉, 지리 정보를 말함.- 인기있는
items또는 트렌드items- 소셜 그래프. 즉, 친구가 좋아하거나 추천한
items
시스템은 이러한 다양한 소스를 공통 후보 풀(pool)로 결합한 다음, 단일 모델로 점수를 매기고 해당 점수에 따라 순위를 매긴다. 예를 들어, 시스템은 다음과 같은 경우에 사용자가 YouTube에서 영상을 시청할 확률을 예측하도록 모델을 학습할 수 있다.
query특성 : 사용자 시청 기록, 언어, 국가, 시간items특성 : 제목, 태그, 영상 임베딩
그런 다음, 시스템은 모델의 예측에 따라 후보 풀에서 영상의 순위를 지정할 수 있다.
후보 생성기가 점수를 매길 수 없는 이유는 무엇인가? (Why not let the candidate generator score?)
후보 생성기는 점수(예: 임베딩 공간의 유사도 측정)를 계산하므로, 순위도 지정하도록 유도할 수 있다. 그러나, 다음과 같은 문제가 있기 때문에 바람직하지 못하다.
- 일부 시스템은 여러 후보 생성기에 의존한다. 이러한 다양한 생성기의 점수는 비교할 수 없다.
- 후보 풀이 작을수록, 시스템은 데이터의 내용을 더 잘 포착할 수 있도록 더 많은 특성과 더 복잡한 모델을 사용할 여유가 있다.
채점을 위한 목적 함수 선택 (Choosing an Objective Function for Scoring)
채점 기능의 선택은 items의 순위와 궁극적으로 추천의 품질에 큰 영향을 줄 수 있다. 예를 들어보자.
- 클릭률 극대화
- 채점 기능이 클릭에 최적화되면, 시스템에서 클릭 미끼 동영상을 추천할 수 있다. 이 채점 기능은 클릭은 하게 만들 수 있겠지만, 좋은 사용자 경험은 제공하지 않는다. 따라서, 사용자의 관심은 빠르게 사라질 수 있다.
- 시청 시간 극대화
- 채점 기능이 시청 시간에 최적화된 경우, 시스템은 매우 긴 영상을 추천할 수 있으며, 이로 인해 사용자 경험이 저하될 수 있다. 여러 개의 짧은 시청이 하나의 긴 시청만큼 좋을 수 있다.
- 다양성 증대 및 세션 시청 시간 극대화
- 더 짧은 동영상을 추천하지만, 사용자의 참여를 유지할 가능성이 더 높은 영상을 추천한다.
채점의 위치적 편향 (Positional Bias in Scoring)

화면 하단에 표시되는 items는 화면 상단에 표시되는 items보다 클릭될 가능성이 적다. 그러나 영상을 채점할 때, 시스템은 일반적으로 해당 영상에 대한 링크가 화면의 어디에 표시되는지 알지 못한다. 가능한 모든 위치에 모델을 쿼리하는 것은 너무 많은 비용이 든다. 여러 위치를 쿼리할 수 있다고 하더라도, 시스템은 여러 순위 점수에서 일관된 순위를 찾지 못할 수 있다.
해결책 (Solution)
- 위치 독립적인 순위를 만든다.
- 모든 후보자를 화면의 최상위 위치에 있는 것처럼 순위를 매긴다.
순위 재지정 (Re-ranking)
추천 시스템의 마지막 단계에서, 시스템은 추가 기준이나 제약 조건을 고려하기 위해 후보의 순위를 재지정할 수 있다. 순위 재지정 방식 중 하나는 일부 후보를 제거하는 필터를 사용하는 것이다.
예시: 다음을 수행하여 영상 추천 모델의 순위 재지정을 구현할 수 있다.
1. 영상이 클릭 미끼인지 여부를 감지하는 별도의 모델을 학습한다.
2. 후보 목록에서 이 모델을 실행한다.
3. 모델이 클릭 미끼로 분류하는 영상을 제거한다.
또 다른 순위 재지정 방법은 순위 지정기가 반환한 점수를 수통으로 변환하는 것이다.
예시: 시스템은 다음 기능으로 점수를 수정하여 영상의 순위를 제공한다.
- 영상의 생성 시기 (아마도 새로운 컨텐츠를 홍보하기 위해)
- 영상의 길이
새로움, 다양성, 공정성에 대해 간단히 알아보자. 이 요소들은 추천 시스템을 개선하는 데 도움이 될 수 있다. 이러한 요소 중 일부는 종종 프로세스의 여러 단계를 수정해야 한다. 각 요소별로 개별적으로 또는 집합적으로 적용할 수 있는 솔루션을 알아보자.
새로움 (Freshness)
대부분의 추천 시스템은 현재 사용자 기록 및 최신 items와 같은 최신 사용 정보를 통합하는 것을 목표로 한다. 모델을 최신 상태로 유지하는 것은, 모델이 좋은 추천을 만드는 데 도움이 된다.
Solution
- 가능한 한 자주 학습을 다시 실행하여 최신 학습 데이터를 학습한다. 모델이 처음부터 다시 학습할 필요가 없도록 학습을 warm-starting하는 것이 좋다. Warm-starting은 훈련 시간을 크게 줄일 수 있다. 예를 들어 행렬 분해 에서, 모델의 이전 인스턴스에 있었던
items에 대한 임베딩을 warm-starting 한다. - 행렬 분해 모델에서 새 사용자를 나타내는 ‘평균’ 사용자를 만든다. 각 사용자에 대해 동일한 임베딩이 필요하지 않다. 사용자 특성을 기반으로 사용자 클러스터를 생성할 수 있다.
- softmax 모델이나 two-tower 모델과 같은 DNN 모델을 사용한다. 모델은 특성 벡터를 입력으로 사용하기 때문에, 학습 중에 표시되지 않은
query또는items에 대해 실행할 수 있다. - 파일의 연령을 특성으로 추가한다. 예를 들어, YouTube는 영상의 연령이나 마지막으로 시청한 시간을 특성으로 추가할 수 있다.
다양성 (Diversity)
시스템이 항상 query 임베딩에 ‘가장 가까운’ items를 추천한다면, 후보는 서로 매우 유사해지게 될 것이다. 이러한 다양성의 부족은 좋지 않거나, 지루한 사용자 경험을 유발할 수 있다. 예를 들어, YouTube에서 사용자가 현재 보고 있는 영상과 매우 유사한 영상만 추천한다면 사용자는 금방 흥미를 잃을 것이다.

Solution
- 서로 다른 소스를 사용하여 여러 후보 생성기를 학습시킨다.
- 다른 목적 함수를 사용하여 여러 순위 지정기를 학습시킨다.
- 다양성을 보장하기 위해 장르 또는 기타 메타데이터를 기반으로
items의 순위를 재지정한다.
공정성 (Fairness)
모델은 모든 사용자를 공정하게 다뤄야 한다. 따라서 모델이 학습 데이터에서 무의식적인 편향을 학습하지 않는지 확인해야 한다.
Solution
- 설계 및 개발에 다양한 관점을 포함한다.
- 포괄적인 데이터 세트에서 ML 모델을 학습시킨다. 데이터가 너무 희박한 경우(예: 특정 카테고리가 과소 표현되는 경우)에는 보조 데이터를 추가한다.
- 편향을 관찰하기 위해, 각 인구 통계에 따른 metrics(예: 정확도 및 절대 오차 등)를 추적한다.
- 소외된 그룹에 대한 별도의 모델을 만든다.
※ 참고
Google Developer - Retrieval
Google Developer - Scoring
Google Developer - Re-ranking