
정규화 : 단순성 (Regularization for Simplicity)
L2 정규화 (L2 Regularization)
다음과 같이, 학습 횟수에 대한 training set과 validation set의 loss를 보여주는 일반화 곡선이 있다고 가정하자.
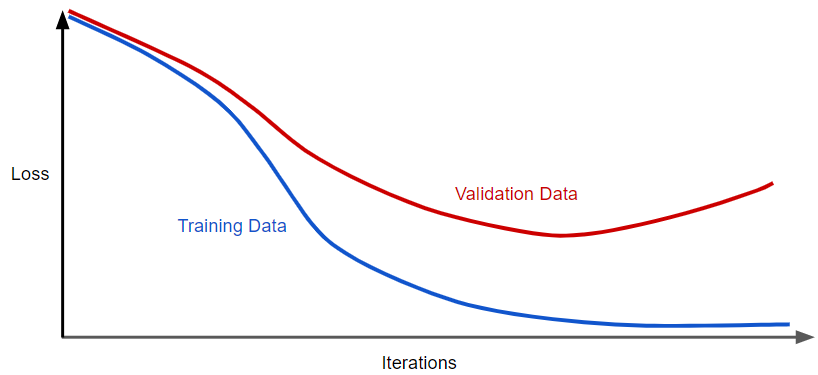
위의 그림을 보면, 모델의 training loss는 서서히 감소하지만 validation loss는 결국 증가하는 것을 볼 수 있다. 즉, 이 일반화 곡선은 모델이 training set의 데이터에 대해서 과대적합되고 있다는 것을 보여준다. 이전에 포스팅 했던 ‘오컴의 면도날’을 활용하여, 복잡한 모델에 페널티를 부여하는 원칙인 ‘정규화’를 통해 과적합을 방지할 수 있다.
즉, 단순히 손실을 최소화하는 것을(경험적 위험 최소화:empirical risk minimization) 목표로 하는 대신,
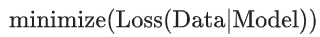
이제는 손실에 더해 복잡도까지 최소화할 것이다. 이를 구조적 위험 최소화(structural risk minimization)라고 부른다.
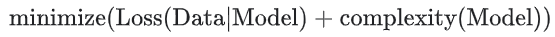
위의 두 식을 보고 알 수 있듯이, 학습 최적화 알고리즘은 모델이 데이터에 얼마나 잘 맞는지를 측정하는 손실 항과, 모델 복잡도을 측정하는 정규화 항이라는 두 가지 항의 함수이다.
지금 공부하는 과정에서는 두 가지의 모델 복잡도을 생각하는 방법에 중점을 둔다.
- 모델에 있는 모든 특성의 가중치의 함수로서의 모델 복잡도
- 가중치가 0이 아닌 특성들의 총 수의 함수로서의 모델 복잡도 (좀 뒤에 이 접근 방식을 다룰 것이다.)
만약 모델 복잡도가 가중치의 함수라면, 절대값이 높은 특성 가중치는 절대값이 낮은 특성 가중치보다 복잡하다.
모든 특성 가중치의 제곱의 합으로 정규화 항을 정의하는 L2 정규화 공식을 사용하여 복잡도를 정량화할 수 있다.
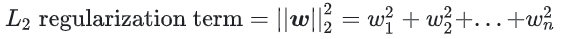
이 공식에서, 0에 가까운 가중치는 모델 복잡도에 거의 영향을 미치지 않는 반면, 이상값 가중치는 큰 영향을 영향을 미칠 수 있다.
예를 들어, 다음과 같은 가중치를 갖는 선형 모델이라면,
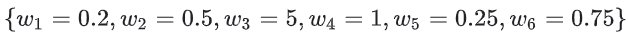
L2 정규화 항의 값은 26.915 이다.
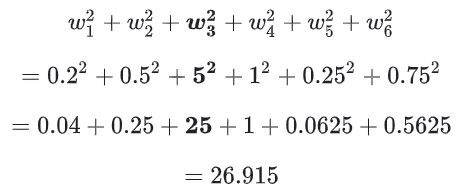
위의 계산을 보면, w3의 제곱값은 25로 복잡도 값의 대부분을 차지한다. 다른 5개의 가중치의 제곱의 합은 L2 정규화 항에 1.915만을 추가한다.
람다 (Lambda)
모델 개발자는 해당 값에 람다(정규화 비율이라고도 함)라는 스칼라를 곱하여 정규화 항의 전반적인 영향을 조정한다. 즉, 모델 개발자는 다음을 목표로 한다.
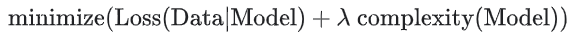
L2 정규화를 수행하면 모델에 다음과 같은 효과가 있다.
- 가중치 값을 0으로 유도한다. (그렇다고 정확히 0이 되는 것은 아니다.)
- 정규 분포(종 모양 분포 또는 가우스 분포)를 사용하여 가중치의 평균을 0으로 유도한다.
람다 값을 높이면 정규화 효과가 강화된다. 예를 들어, 높은 람다 값에 대한 가중치의 히스토그램은 다음과 같이 보일 수 있다.
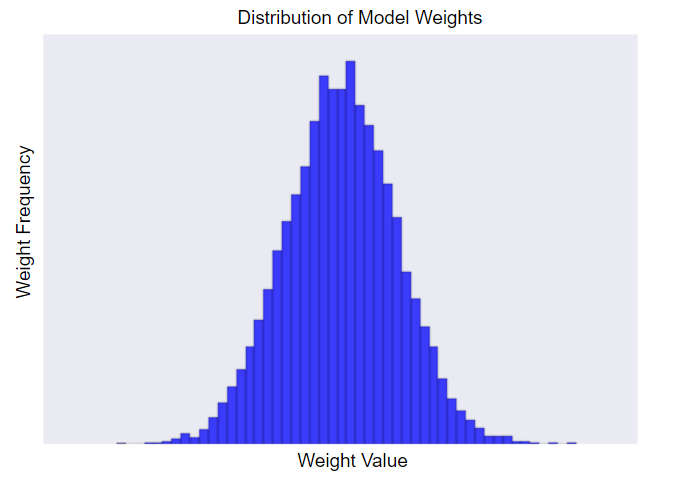
람다 값을 낮추면 더 평평한 히스토그램이 생성된다.
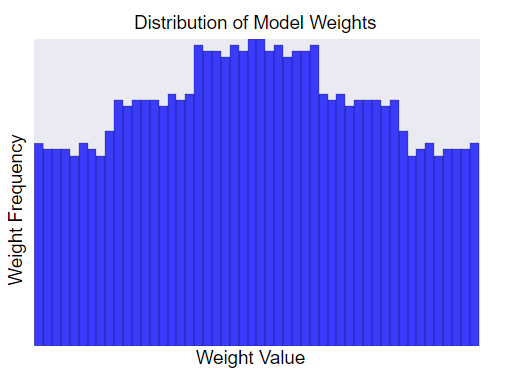
람다 값을 설정할 때의 목표는 단순성과 학습 데이터 사이의 올바른 균형을 맞추는 것이다.
- 람다 값이 너무 높으면 모델은 단순해지겠지만 데이터에 대해 과소적합할 위험이 있다. 모델이 충분히 학습하지 않아 좋은 예측을 하지 못할 것이다.
- 람다 값이 너무 낮으면 모델은 더 복잡해지며 데이터에 대해 과대적합할 위험이 있다. 모델은 특히 training data에 대해 너무 많이 학습하여 새로운 데이터에 일반화할 수 없을 것이다.
람다를 0으로 설정하면 정규화가 완전히 제거된다. 이 경우, 학습은 손실을 최소화하는 데만 초점을 맞추며, 이는 과대적합에 대해 가장 높은 위험을 가진다.
람다의 이상적인 값은 실제의 새로운 데이터에 일반화가 잘 되는 모델을 생성한다. 하지만 불행히도, 람다의 이상적인 값은 데이터에 따라 달라지기 때문에, 각 데이터에 따른 조정을 해야한다.
learning rate와 람다 사이에는 밀접한 관련이 있다. 강력한 L2 정규화 값은 특성 가중치를 0에 가깝게 만드는 경향이 있다. learning rate가 작을수록(Early stopping 포함) 0에서 멀어지는 단계가 크지 않기 때문에 자주 같은 효과를 생성한다. 결과적으로, learning rate와 람다를 동시에 조정하면 오히려 모델을 교란시키는 효과가 발생할 수 있다.
Early stopping은 모델이 완전히 수렴되기 전에 학습을 종료하는 것을 말한다. 실제로, 종종 온라인 방식으로 모델을 학습할 때 어느 정도의 암시된 early stopping으로 종료된다. 즉, 일부 새로운 추세에는 아직 수렴할 데이터가 충분하지 않다.
언급한 바와 같이, 정규화 매개변수를 변경하는 것으로부터의 효과는 learning rate나 학습의 반복 횟수를 바꾸는 것으로부터의 효과와 혼동될 수 있다. 이를 위한 한 가지 유용한 방법은(batch_size가 고정되어 있을 때) early stopping이 문제가 되지 않을 만큼 충분히 많은 반복 횟수를 학습하는 것이다.
※ 참고
Google Developer - L2 Regularization
Google Developer - Lambda