
Loss 감소 시키기(Reducing Loss)
반복적 접근(Iterative Approach)
반복 학습은 숨겨진 물건을 찾기 위한 미국의 ‘Hot and Cold’ 게임과 비슷할지도 모른다. 이 게임은 숨겨진 물건에 가까워지면 ‘hot’, 멀어지면 ‘cold’라고 말해주는 게임이다. 이 게임에서 ‘숨겨진 물건’은 가능한 최고의 모델이다. 무작위 추측으로 시작하고(예: 가중치-0) 시스템이 loss의 값을 말해줄 때까지 기다린다. 그러고 나서, 다른 추측으로(예: 가중치-0.5) 시도하고 다시 loss를 측정한다. 이 게임을 제대로 했다면, 점점 따듯해질 것이다. 이 게임의 진정한 비결은 가능한 한 효율적으로 최고의 모델을 찾아내는 것이다.
다음 그림은 머신러닝 알고리즘이 모델을 훈련시키기 위해 사용하는 반복적인 시행착오 과정을 보여준다.
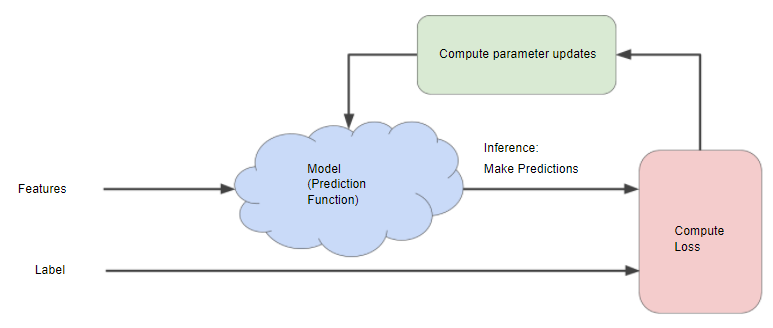
이 반복 전략은 머신러닝에서 일반적으로 사용되는데, 그 주된 이유는 대규모 데이터 세트에 맞게 확장되기 때문이다.
모델은 하나 이상의 특징을 입력값으로 받고 하나의 예측(y’)을 반환한다. 간단히 설명하기 위해 변수가 하나인 모델이 있다고 가정하자.
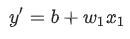
편향(b)과 가중치(w1)에 대해서 어떤 초기 값을 설정해야 하는가? 선형 회귀 문제의 경우에서는, 시작하는 값은 중요하지 않은 것으로 나타났다. 임의의 값을 선택할 수 있지만, 대신 다음과 같이 사소한 값을 사용한다.
- b = 0
- w1 = 0
특성값이 10이라고 가정했을 때, 모델의 예측 함수에 입력하면 다음과 같다.
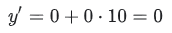
그 후, 이 전의 글에서 설명했던 손실 함수인 L2 loss를 통해 loss를 계산한다면, 두 가지의 입력값이 필요하다.
- y : 특성값 x에 대한 모델의 예측값
- y’ : 특성값 x의 실제 레이블값
이렇게 “매개변수(parameter)를 갱신하는 연산”은 머신러닝 시스템이 손실 함수의 값을 확인하고 편향과 가중치에 대한 새로운 값을 생성한다. 그리고 알고리즘이 가능한 가장 낮은 loss 값을 가진 모델 매개변수를 찾을 때까지 학습을 반복한다. 일반적으로 총 손실이 변경되지 않거나, 최소한 매우 느리게 변경될 때까지 반목한다. 이런 상황이 되었을 때, ‘모델이 수렴되었다.’라고 말한다.
경사 하강법(Gradient Descent)
가중치(w)의 모든 가능한 값에 대한 loss를 계산할 시간과 컴퓨팅 리소스가 있다고 가정하자. 우리가 이전에 조사한 회귀 문제의 경우 ‘loss vs. 가중치’의 그래프는 항상 볼록하다. 즉, 그래프는 항상 다음과 같은 그릇 모양이 된다.
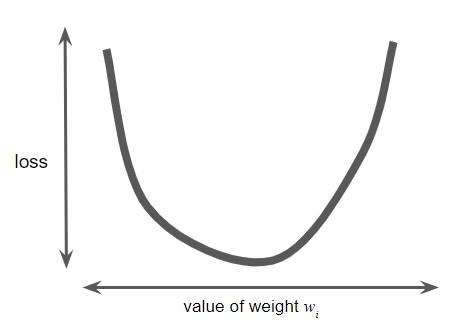
볼록 문제에는 최소값이 오직 하나만 존재한다. 즉, 기울기가 정확히 0인 곳은 한 곳뿐이다. 이 최소값은 손실 함수가 수렴하는 곳이다.
수렴 포인트를 찾기 위해 전체 데이터 세트에서 가능한 모든 가중치 값에 대한 손실 함수를 계산하는 것은 비효율적인 방법이다. 따라서, 경사 하강법을 사용한다.
경사 하강법의 첫 번째 단계는 가중치의 시작점(초기값)을 정하는 것이다. 시작점은 별로 중요하지 않다. 따라서 많은 알고리즘은 단순히 가중치의 초기값을 0으로 설정하거나 임의의 값을 선택한다. 다음 그림은 초기값을 0보다 약간 크게 설정한 것을 확인 할 수 있다.
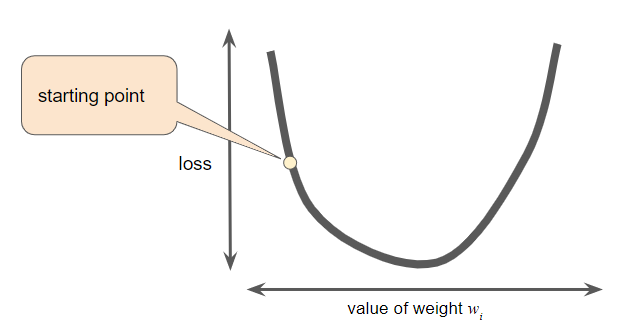
초기값을 설정한 후, 경사 하강 알고리즘은 시작점에서 곡선의 기울기(gradient)를 계산한다. 위의 그림에서 loss의 기울기는 곡선의 미분값(기울기)과 같으며, 이 글의 시작 부분에 언급한 ‘Hot and Cold’ 게임에 비유하여, ‘hot’인지 ‘cold’인지 최소값에 대한 방향을 알려준다. 가중치가 여러 개인 경우, 기울기(gradient)는 가중치에 대한 편미분의 벡터이다.
기울기(gradient)는 벡터이기 때문에 다음과 같은 특성을 갖는다.
- 방향 (direction)
- 크기 (magnitude)
기울기(gradient)는 항상 손실 함수에서 가장 가파르게 증가하는 뱡향을 가리킨다. 경사 하강 알고리즘은 loss를 가능한 한 빠르게 줄이기 위해 기울기가 작아지는 방향으로 수행한다.
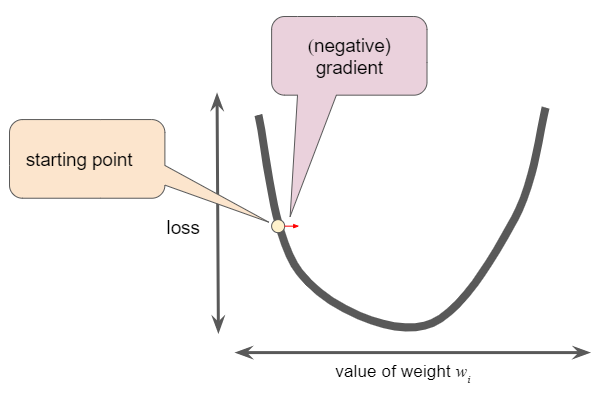
손실 함수 곡선을 따라 다음 포인트를 정하기 위해, 경사 하강 알고리즘은 다음 그림과 같이 기울기 크기의 일부를 시작점에 더한다.
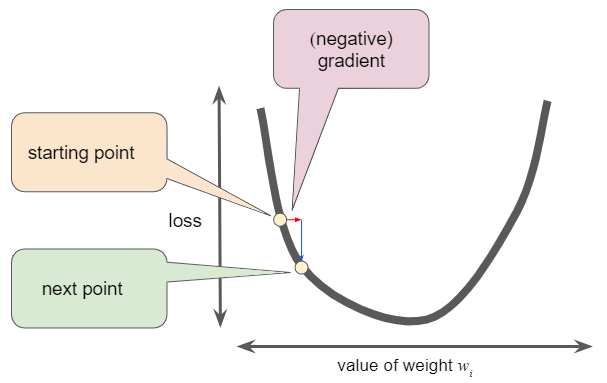
이와 같은 과정을 반복하여 손실 함수가 최소값에 점점 가까워지는 것이다.
Learning Rate
언급한 바와 같이, 경사(gradient) 벡터는 방향과 크기를 모두 갖는다. 경사 하강 알고리즘은 다음 포인트를 결정하기 위해 경사에 learning rate(step size라고도 함)이라는 스칼라를 곱한다. 예를 들어, 경사의 크기가 2.5이고 learning rate가 0.01이라고 할 때, 경사 하강 알고리즘은 이전 포인트로부터 0.025 떨어진 지점을 다음 포인트로 정한다.
하이퍼파라미터(Hyperparameter)들은 프로그래머가 머신러닝 알고리즘을 조정하는 노브이다. 대부분의 머신러닝 프로그래머는 learning rate를 조정하는데 상당한 시간을 보낸다. 만약 learning rate를 너무 작게 정했다면, 학습 시간이 매우 길어질 것이다.
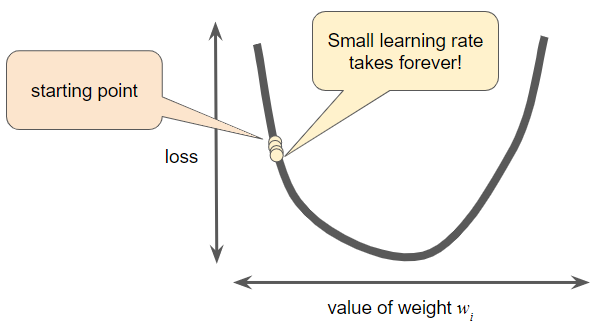
반대로, leearning rate를 너무 크게 설정하면 다음 포인트는 잘못된 양자 역학 실험처럼 최소값을 가로질러 끊임없이 튕겨 나갈 것이다.
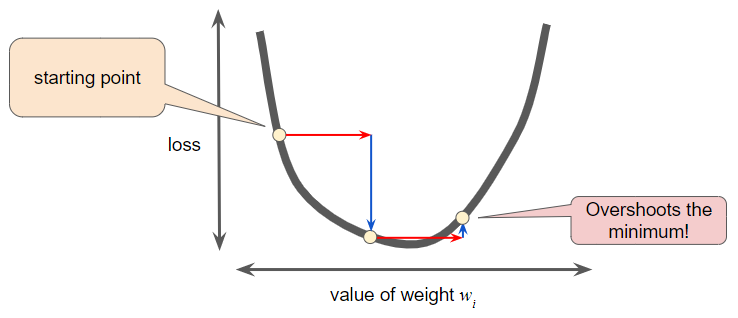
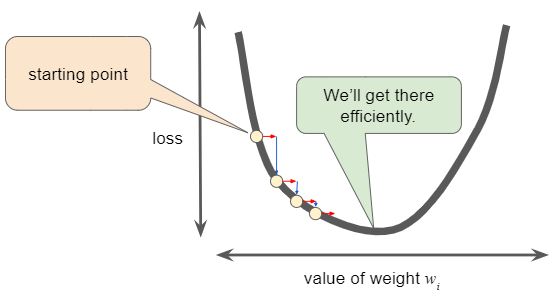
모든 회귀 문제에는 Goldilocks learning rate가 있다. (‘Goldilocks 원리’라는 것이 있는데 링크를 걸겠다.) 이 Goldilocks 값은 손실 함수가 얼마나 평평한지와 관련이 있다. 만약 손실 함수의 경사(gradient)가 작다는 것을 알고 있다면 더 큰 learning rate를 안전하게 시도할 수 있으며, 이는 최적의 횟수로 최소값으로 향할 수 있는 결과가 된다.
1차원에서 이상적인 learning rate는 x에 대한 f(x)의 2차 도함수의 역이다.
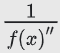
2차원 혹은 그 이상의 차원에서 이상적인 learning rate는 Hessian matrix(2차 편도함수의 정방 행렬)의 역이다.
즉, 학습 시에 설계하는 모델에 따라 learning rate를 적절하게 키우거나 줄이거나 하면서 최소의 반복 학습으로 최소값에 도달하도록 learning rate를 최적화시키는 것이 중요하다.
확률적 경사 하강법 (Stochastic Gradient Descent)
경사 하강법에서, batch는 단일 반복에서 경사(gradient)를 계산하는 데 사용하는 총 데이터 수이다. 지금까지는 batch가 전체 데이터 세트라고 가정해왔다. 하지만 빅데이터를 활용하여 작업을 할 때 데이터 세트에 수천만을 넘어 수천억 개의 데이터도 포함된다. 뿐만 아니라, 방대한 수의 특징들(features)도 포함하고 있다. 따라서, batch는 거대해진다. 이 batch가 매우 크면 단일 반복이라도 연산하는 데 매우 오랜 시간이 걸릴 것이다.
무작위로 샘플링된 데이터가 있는 대규모 데이터 세트는 중복 데이터가 포함될 수 있다. 실제로 batch size가 커질수록 중복 가능성도 높아진다. 약간의 중복성은 노이즈가 심한 경사(gradient)를 부드럽게 하는 데 유용할 수 있지만, 대규모 배치는 적당히 큰 배치 보다 훨씬 예측치를 전달하지 못하는 경향이 있다.
평균적으로 훨신 적은 계산을 통해 적절한 경사(gradient)를 얻을 수 있다면 어떨까? 데이터 세트에서 무작위로 데이터를 선택함으로써 비록 노이즈가 있더라도 훨씬 작은 batch에서 큰 평균을 추정해 낼 수 있었다. 확률적 경사 하강법(SGD:Stochastic Gradient Descent)은 이 아이디어를 사용하여 각 반복당 하나의 데이터만 사용한다. 충분한 반복이 주어지면 SGD는 작동하지만 매우 노이즈가 크다. ‘확률적’이라는 용어는 각 배치를 구성하는 하나의 데이터가 랜덤으로 선택되는 것을 나타낸다.
미니 배치 확률적 경사 하강법(Mini-batch SGD)은 전체 배치와 SGD 사이의 절충안이다. 미니 배치는 일반적으로 무작위로 선택된 10개에서 1,000개 사이의 데이터를 사용한다. 미니 배치 SGD는 SGD의 노이즈 양을 줄이지만 여전히 전체 배치보다 효율적이다.
즉, batch size가 클수록 정확도는 좋지만, 연산량이 굉장히 크고 학습하는 시간도 훨씬 길다. 반면 batch size가 작아질수록 정확도는 약간 떨어질 수 있지만, 연산량과 학습 시간의 측면에서 더 효율적인 학습 방법이 될 수 있다.
※ 참고
Google Developer - An Iterative Approach
Google Developer - Gradient Descent
Google Developer - Learning Rate
Google Developer - Stochastic Gradient Descent