
추천 시스템: 후보 생성 (Candidate Generation)
후보 생성 개요 (Candidate Generation Overview)
후보 생성은 추천 시스템의 첫 번째 단계이다. query가 주어지면, 시스템은 관련 후보 세트를 생성한다. 다음 표는 두 가지 일반적인 후보 생성 방식을 보여준다.

콘텐츠 기반 필터링 (content-based filtering)
items간의 유사도를 활용하여 사용자가 좋아하는 것과 유사한items를 추천한다.
예를 들어, 사용자 A가 두 개의 귀여운 고양이 영상을 본 경우, 시스템은 해당 사용자에게 귀여운 동물 영상을 추천할 수 있다.
협업 필터링 (collaboative filtering)
query와items간의 유사성을 동시에 사용하여 추천한다.
예를 들어, 사용자 A가 사용자 B와 유사하고, B가 영상 1을 좋아한다면, 시스템은 A가 영상 1과 유사한 영상을 본 적이 없더라도 A에게 영상 1을 추천할 수 있다.
임베딩 공간 (Embedding Space)
콘텐츠 기반 필터링과 협엽 필터링 모두 공통 임베딩 공간 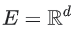 의 임베딩 벡터에 각
의 임베딩 벡터에 각 items과 각 query를 매핑한다. 일반적으로, 임베딩 공간은 저차원이며(즉, d는 코퍼스의 크기보다 훨씬 작다.) items 또는 query 세트의 일부 잠재 구조를 반영한다. 일반적으로 동일한 사용자가 시청하는 YouTube 영상과 같은 유사한 items는 임베딩 공간에서 서로 가깝게 표시된다. 여기서 “가깝게”의 개념은 유사성의 척도로 정의된다. 가까우면 유사함, 멀면 유사하지 않음.
유사도 측정 (Similarity Measure)
유사도 측정은 한 쌍의 임베딩을 취하여 유사도을 측정하는 스칼라를 반환하는 함수 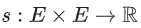 이다. 임베딩은 다음과 같이 후보 생성에 사용할 수 있다.
이다. 임베딩은 다음과 같이 후보 생성에 사용할 수 있다. query 임베딩 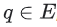 가 주어지면, 시스템은 q에 가까운
가 주어지면, 시스템은 q에 가까운 items 임베딩 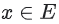 , 즉 높은 유사도
, 즉 높은 유사도 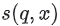 를 가진 임베딩을 찾는다.
를 가진 임베딩을 찾는다.
유사도를 측정하기 위해, 대부분의 추천 시스템은 다음 중 하나 이상을 사용한다.
- 코사인 (cosine)
- 내적 (dot product)
- 유클리드 거리 (Euclidean distance)
코사인 (Cosine)
- 코사인 유사도는 단순히 두 벡터 사이의 각도의 코사인이다.
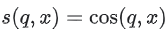
내적 (Dot Product)
- 두 벡터의 내적은
이다. 또한,
(각의 코사인에 놈(norm)의 곱을 곱한 값)으로 표시된다. 따라서 임베딩이 정규화되면 내적과 코사인이 일치한다.
유클리드 거리 (Euclidean distance)
- 유클리드 거리는 유클리드 공간의 일반적인 거리
이다. 거리가 작을 수록 유사도가 높아진다. 임베딩이 정규화되면, 이 경우 유클리드 거리의 제곱은
이기 때문에, 상수까지 내적(및 코사인)과 일치한다.
유사도 측정 비교 (Comparing Similarity Measures)
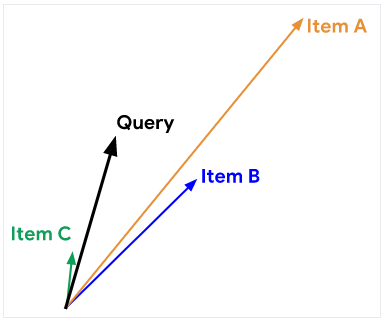
위와 그림과 같은 예가 있다고 가정하자. 검은색 벡터는 query 임베딩을 보여준다. 다른 세 개의 임베딩(items: A, B, C)은 후보 items를 나타낸다. 사용된 유사도 측정에 따라 items의 순위가 다를 수 있다.
이미지를 사용하여 위에서 공부한 세 가지 유사도 측정(코사인, 내적, 유클리드 거리)을 모두 사용하여 items 순위를 결정하려고 한다.
- A는 가장 큰 놈(norm)을 가지며, 내적을 사용하면 1위이다.
- B는
query에 물리적으로 가장 가깝기 때문에 유클리드 거리를 사용하면 1위이다. - C는
query와 가장 작은 각도를 가지며, 코사인 유사도를 사용하면 1위 이다.

어떤 유사도 측정을 선택할 것인가?
코사인에 비해 내적의 유사도는 임베딩의 놈(norm)에 민감하다. 즉, 임베딩의 norm이 클수록 유사도(예각 items에 대해)가 높고 추천될 가능성이 높아진다. 이는 다음과 같은 추천에 영향을 줄 수 있다.
-
training set에 매우 자주 등장하는
items(예: 인기 있는 YouTube 영상)에는 큰 norm을 가진 임베딩이 있는 경향이 있다. 인기 정보를 반영하는 것이 바람직하다면 내적을 사용하는 것이 좋다. 그러나, 주의하지 않으면 인기 있는items이 추천 항목을 지배할 수 있다. 실제로item의 norm을 덜 강조하는 유사도 측정의 다른 변형을 사용할 수 있다. 예를 들어, 일부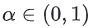 에 대해
에 대해 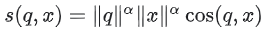 를 정의한다.
를 정의한다. -
아주 드물게 나타나는
items는 학습하는 동안 자주 업데이트되지 않을 수 있다. 결과적으로, 큰 norm으로 초기화되면, 시스템은 관련있는items보다 희귀items를 추천할 수 있다. 이 문제를 방지하기 위해서는, 임베딩 초기화에 주의하고, 적절한 정규화를 사용해야 한다.
※ 참고