
특성 교차 (Feature Crosses)
교차 특성(Feature Cross)은 두 개 이상의 특성을 곱하여(교차)하여 형성된 합성 특성이다. 특성의 교차 조합은 해당 특성들이 개별적으로 제공할 수 있는 것 이상의 예측 능력을 제공할 수 있다.
비선형성 표현하기 (Encoding Nonlinearity)
아래의 그림들의 점의 색은 다음을 나타낸다.
- 파란 점 : 병든 나무
- 노란 점 : 건강한 나무
Figure 1
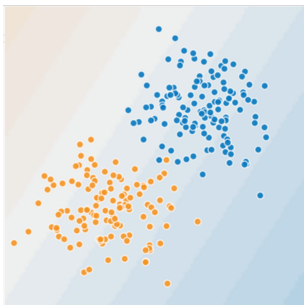
그림 1에서 병든 나무와 건강한 나무를 깔끔하게 구분하는 선을 그릴 수 있는가? 그렇다. 위의 그림은 선형 문제이다. 병든 나무와 건강한 나무의 한 두 그루는 섞여 있기 때문에 완벽한 선은 아니겠지만, 좋은 예측 변수가 될 것이다.
이제 아래의 그림을 보자.
Figure 2
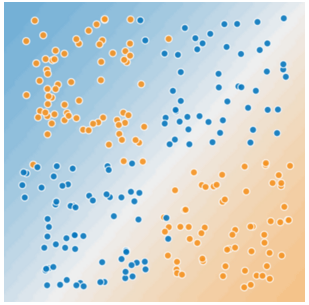
그림 2에서도 하나의 직선을 그려 병든 나무와 건강한 나무를 깔끔하게 나눌 수 있는가? 할 수 없다. 이 그림은 비선형 문제이다. 어떤 선을 그려도 좋지 않은 예측 변수가 될 것이다.
Figure 3. 하나의 선은 두 집합을 나눌 수 없다.
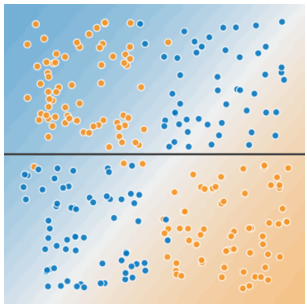
그림 2에 본 비선형 문제를 해결하기 위해서는 교차 특성(feature cross)를 생성해야 한다. 교차 특성은 두 개 이상의 입력 특성을 함께 곱하여 특성 공간의 비선형성을 표현하는 합성 특성이다. (‘교차’라는 용어는 ‘벡터의 외적(cross product)’에서 파생된 것이다.)
특성 x1과 x2를 교차하여 합성 특성 x3를 만들어보자.
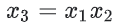
이 새로 생성된 교차 특성 x3를 다른 특성과 마찬가지로 취급하여 선형 공식에 추가하면 다음과 같다.
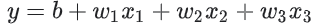
선형 알고리즘은 w1 및 w2와 같이 w3에 대한 가중치를 학습할 수 있다. 즉, w3이 비선형 정보를 표현한다고 해서, 따로 w3의 값을 위해 선형 모델이 학습하는 방식을 변경할 필요는 없다.
교차 특성의 종류(Kind of feature crosses)
많은 종류의 교차 특성을 생성할 수 있다. 예를 들면,
- [A x B] : 두 특성의 값을 곱하여 형성된 교차 특성
- [A x B x C x D x E] : 5개의 특성 값을 곱하여 형성된 교차 특성
- [A x A] : 단일 특징을 제곱하여 형성된 교차 특성
확률적 경사 하강법(Stochastic Gradient Descent) 덕분에 선형 모델을 효율적으로 학습할 수 있다. 결과적으로, 교차 특성으로 확장된 선형 모델을 보완하는 것은 전통적으로 대규모 데이터 세트를 학습하는 효율적인 방법이었다.
Crossing One-Hot Vectors
지금까지는 개별적인 두 개의 실수 특성의 교차 특성에 대해서 중점을 두었다. 그러나 실제로 머신러닝 모델은 연속되는 특성을 거의 교차하지 않는다. 하지만 one-hot 특성 벡터는 빈번하게 교차한다. ont-hot 특성 벡터의 교차는 논리적 결합으로서 생각해야 한다. 예를 들어, country와 language라는 두 개의 특성이 있다고 가정하자. 이에 대해 각각의 ont-hot encoding을 하면 country=USA, country=France 또는 language=English, language=Spanish로 해석될 수 있는 이진(binary) 특성 벡터를 생성한다. 그리고나서, 이러한 one-hot encoding의 특성 교차를 수행하면 다음과 같이 논리적 결합으로 해석될 수 있는 이진 특성을 얻을 수 있다.
country:usa AND language:spanish
또 다른 예로, 위도와 경도를 binning하여 5개 요소로 구성된 one-hot 특성 벡터를 생성한다고 가정하자. 그럼 주어진 위도와 경도를 다음과 같이 나타낼 수 있다.
binned_latitude = [0, 0, 0, 1, 0]
binned_longitude = [0, 1, 0, 0, 0]
아래와 같이 두 특성의 교차 특성을 생성한다고 생각해보자.
binned_latitude X binned_longitude
이 교차 특성은 25개 요소의 one-hot 벡터(24개의 0과 1개의 1의 값을 갖는)이다. 하나의 1의 값(위도와 경도가 만나는 지점)은 위도와 경도의 특정한 결합을 식별한다. 이해가 잘 안간다면, 5x5의 바둑판 모양의 표에서 x축과 y축을 위도와 경도로 설정하고 어떤 집의 데이터의 위도와 경도에 대해 해당하는 지점은 1 나머지는 모두 0라고 생각하면 된다. 그러면 모델은 해당 결합에 대한 특정 관계를 학습할 수 있다.
아래와 같이 위도와 경도를 훨씬 더 큰 범위로 binning 해보자.
binned_latitude(lat) = [
0 < lat <= 10
10 < lat <= 20
20 < lat <= 30
]
binned_longitude(lon) = [
0 < lon <= 15
15 < lon <= 30
]
그런 다음, 이에 대한 특성 교차를 생성하면 다음과 같은 의미를 같은 합성 특성이 생성된다.
binned_latitude_X_longitude(lat, lon) = [
0 < lat <= 10 AND 0 < lon <= 15
0 < lat <= 10 AND 15 < lon <= 30
10 < lat <= 20 AND 0 < lon <= 15
10 < lat <= 20 AND 15 < lon <= 30
20 < lat <= 30 AND 0 < lon <= 15
20 < lat <= 30 AND 15 < lon <= 30
]
이제 직접 연습을 해보자. 모델이 두 가지 특성을 기반으로 주인이 강아지에 대해 얼마나 만족할지 예측해야 한다고 한다.
- 행동 타입 (짖음, 울음, 달라붙음 등)
- 시간 (00:00 ~ 23:00)
이 두 특성으로 특성 교차를 만든다면,
[행동 타입 X 시간]
원래의 두 특성보다 훨씬 더 대단한 예측 능력을 갖게 될 것이다. 예를 들어, 주인이 직장에서 돌아온 오후 6시에 강아지가 행복하게 울면 주인의 만족도에 대해 긍정적인 예측 변수가 될 가능성이 크다. 그러나 주인이 푹 자고 있을 시간인 새벽 3시에 짖는 것은 주인의 만족도에 대해 강력한 부정적인 예측 변수가 될 것이다.
선형 학습 모델은 대규모 데이터에 잘 확장된다. 방대한 데이터 세트에서 교차 특성을 사용하는 것은 고도로 복잡한 모델을 학습하기 위한 효율적인 전략 중 하나이다. 신경망은 또 다른 전략을 제시하지만, 이건 차례에 맞게 포스팅하겠다.
※ 참고
Google Developer - Encoding Nonlinearity
Google Developer - Crossing One-Hot Vectors